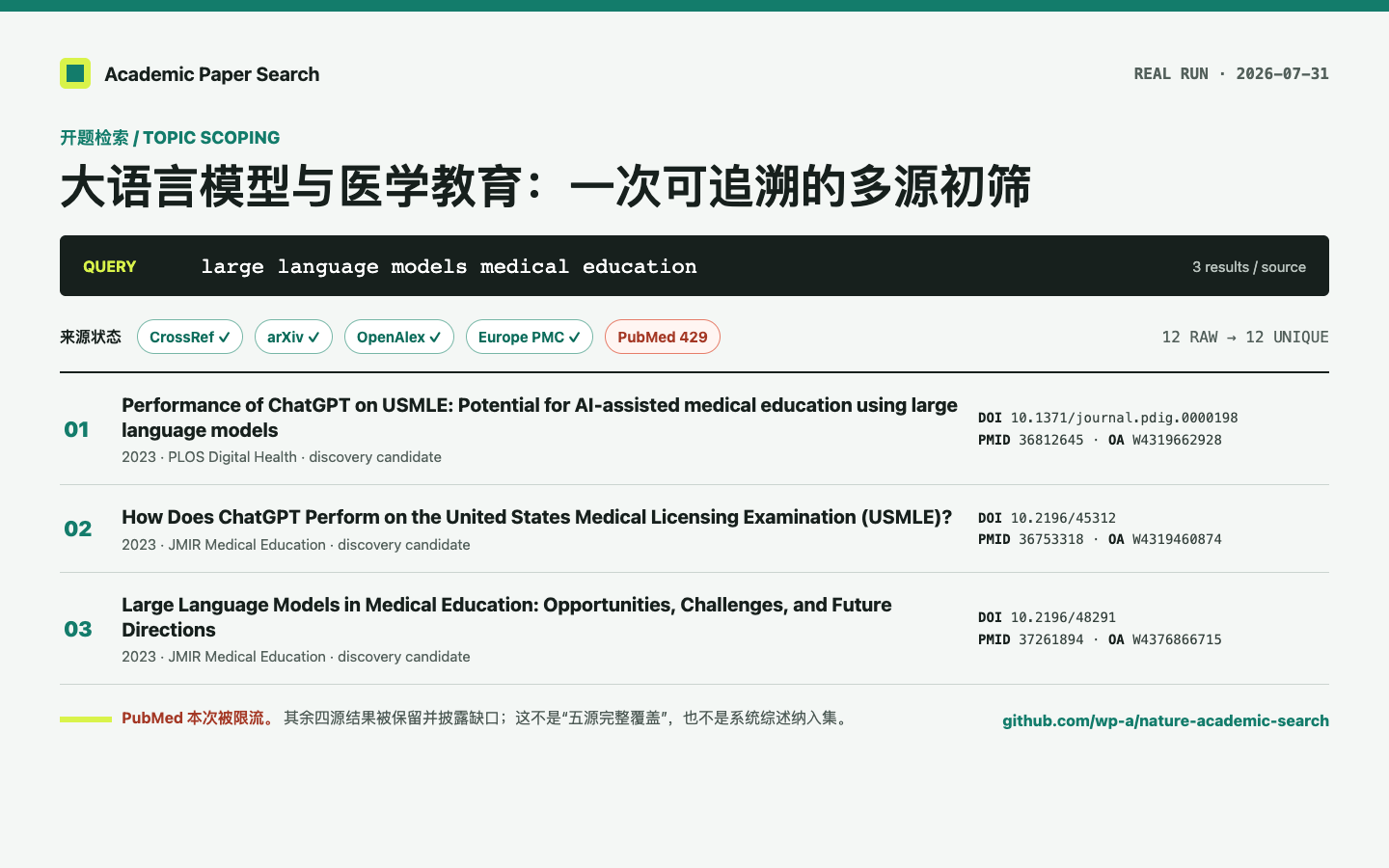
开题检索怎么做:用 Codex / Claude Code 留下一份可复查的文献初筛
用一次真实的五源论文检索演示如何记录查询、识别来源缺口、从候选论文收敛开题问题,并避免把初筛包装成系统综述。

AI 给的论文引用是真的吗?用 DOI / PMID 做四状态核验
用一条故意构造的错误引用演示如何解析 DOI、比较题名作者年份,并以 verified、mismatch、not_found、manual_needed 四种状态交付核验结果。
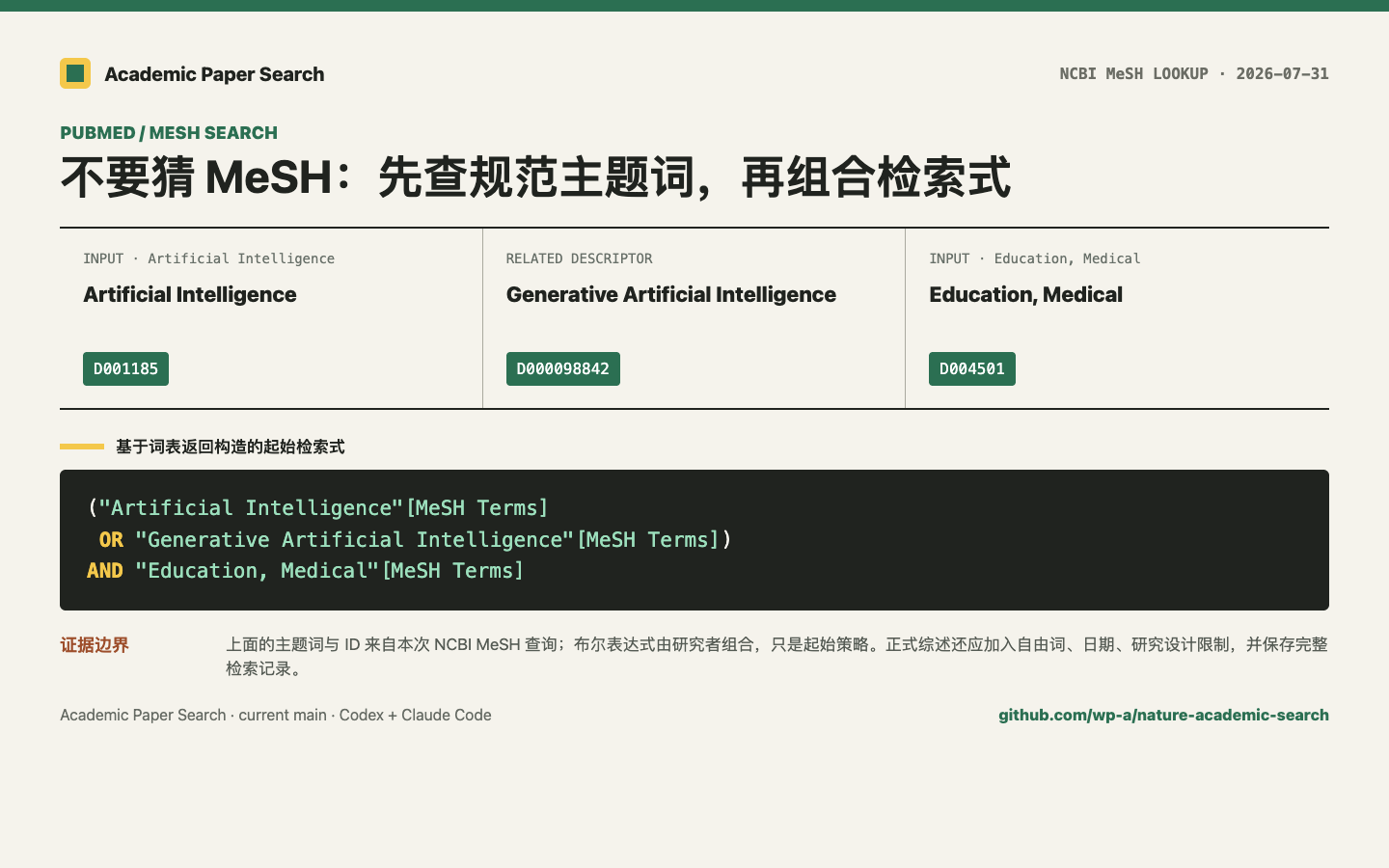
PubMed 检索别只堆关键词:从 MeSH 核对到可复用检索式
用 NCBI MeSH 的真实返回演示如何核对 Artificial Intelligence、Generative Artificial Intelligence 与 Education, Medical,再构建可记录、可补充的 PubMed 起始检索式。
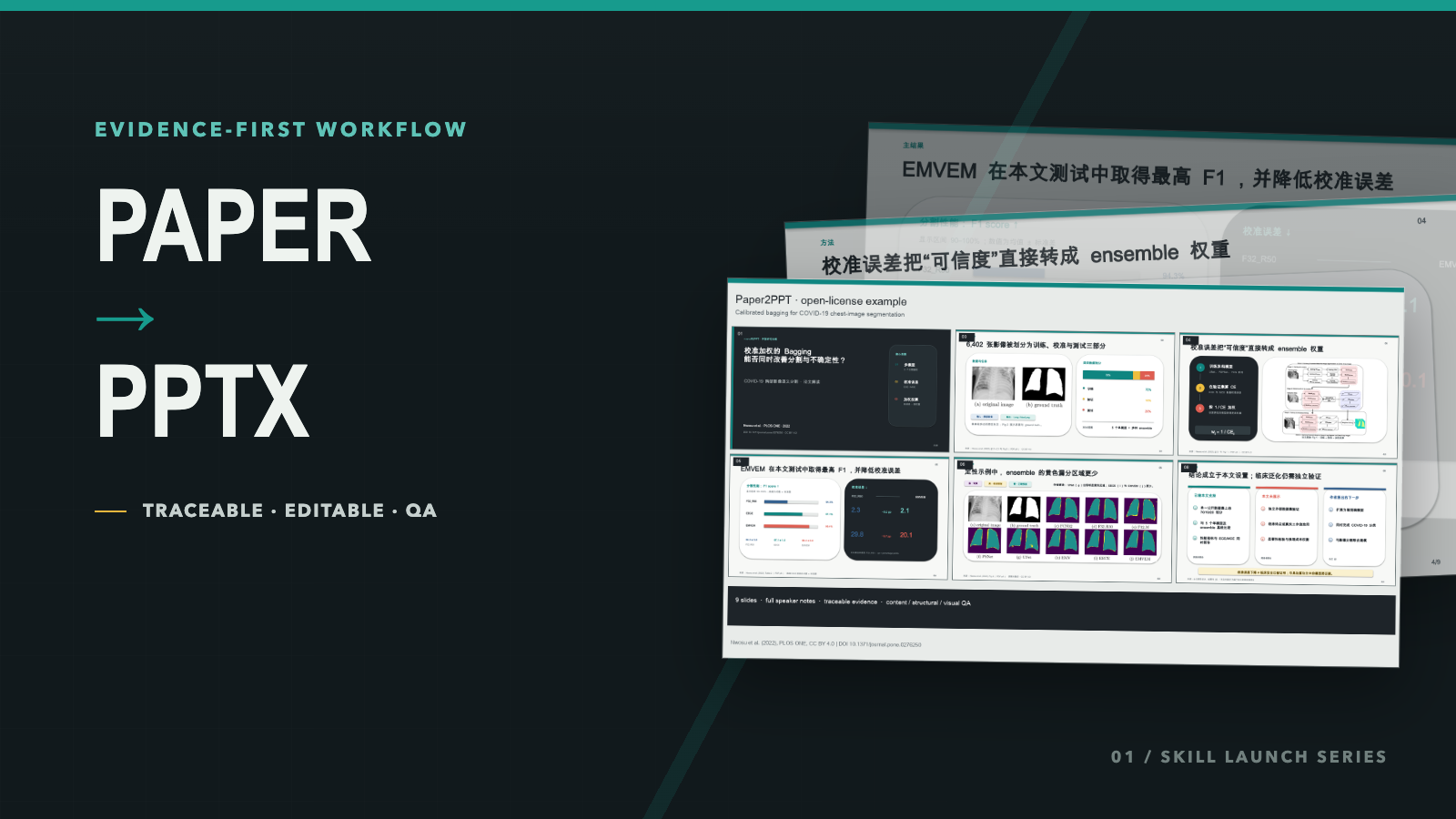
Paper2PPT:从一篇论文到可编辑、可追溯 PPTX 的证据优先工作流
Paper2PPT v0.1.0 正式发布:先建立主张与来源的映射,再生成带讲稿、素材清单和三层质量检查的可编辑学术 PPTX。

Academic Paper Search:可复现的多源文献检索工作流
Academic Paper Search v0.2.0:默认并行检索五个论文源,按需使用 Semantic Scholar 富化,并把 ClinicalTrials.gov 试验与论文严格分开。

PaperRefine:论文润色不只是换同义词,而是让主张回到证据边界
PaperRefine 是一个面向已有论文文本的学术编辑 Skill。它先保护数字、引用与 LaTeX,再诊断论证和校准主张,最后输出可核对的修改稿与作者确认项。
SOL ENGINE:把 GPT-5.6 提示词优化变成可审计、可回归的工程流程
SOL ENGINE 将 GPT-5.6 提示词工程拆成审计、最小优化、受控评测和发布门禁,并提供两个无需 API key 的本地确定性 CLI,帮助团队保留真实契约。
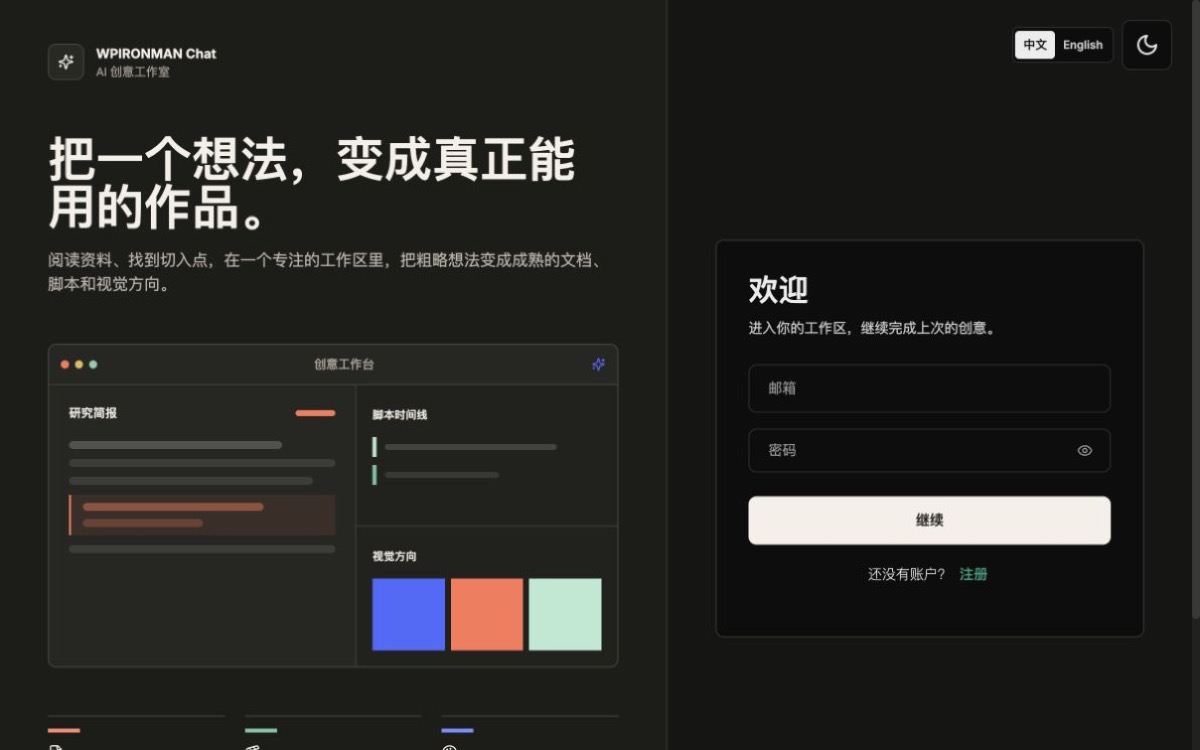
WPIRONMAN Chat 正式上线:产品介绍与使用指南
WPIRONMAN Chat 是一个基于 LibreChat 自托管并完成品牌定制的 AI 工作台。这篇文章介绍它为什么被做出来、现在能做什么,以及如何使用模型、文件、Agent 和工具完成真实任务。

我现在怎么做科研:从文献调研、实验到论文写作
这篇文章记录我现在比较稳定的一套科研流程:用 Deep Research 做前期调研,用远程服务器里的 Codex 跑实验,再把日志、结果和引用整理成论文初稿。

我做了一个学术工作流助手:把选刊、前沿跟踪和 AI 预审串起来
如果只把它叫做“投稿助手”,其实已经有点说窄了。 我现在这个项目更接近一个学术工作流助手:它不是只回答“这篇论文投哪”,而是想把研究者从选刊、看前沿、记截稿、管投稿,到做 AI 预审这一整条链路尽量串起来。 这篇文章就顺着这个思路,介绍一下我现在的项目到底在做什么,以及我为什么会把它做成现在这个样子。 1. 这个项目现在是什么 从代码结构上看,它已经不是单端 App,而是一个多端并行的项目: iOS 端用 SwiftUI,目录在 AcademicSubmission/AcademicSubmission/ Android 端用 Flutter,目录在 academic_submission_flutter/ 微信小程序端用 UniApp + Vue3,目录在 academic-submission-uniapp/ AI 预审后端在 deep_research_review_v2/,走的是一条独立的深度评审链路 其中,iOS 端已经不只是一个静态展示壳了。 从 ContentView.swift...
