
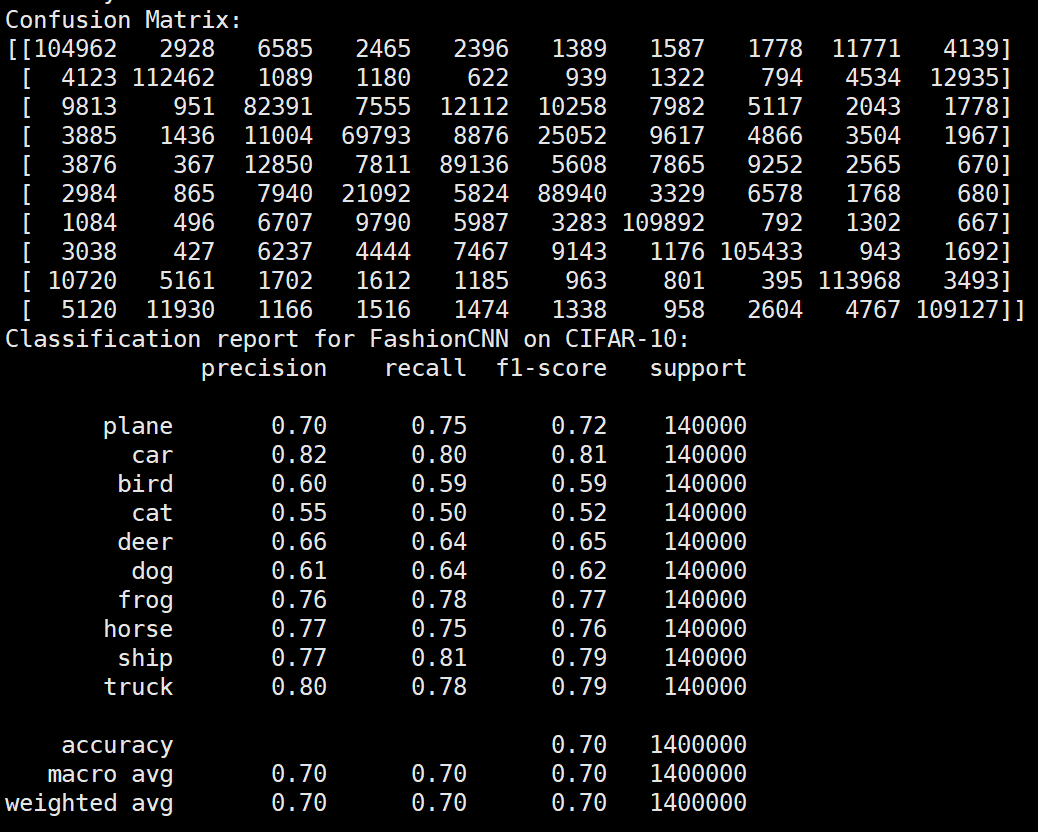
使用ResNet18预训练模型
由于笔记本性能太差,所以在服务器上运行的,显卡配置为4090。经大量实验判断,初始学习率为0.01最后效果较差,所以初始学习率应设为0.001。全部代码代码已上传到:https://github.com/wp-a/-CIFAR10-.git
库函数导入
1 | import matplotlib.pyplot as plt |
数据集加载及增强操作
1 | transform_train = transforms.Compose([ |
加载预训练模型
1 | def get_resnet18(pretrained=True): |
模型训练超参数设置
1 | #定义损失函数,初始学习率,优化器 |
模型训练
1 | num_epochs = 6 |
实验结果保存
1 | torch.save(model.state_dict(), 'resnet18_cifar10.pth') |
实验结果分析
lr分析
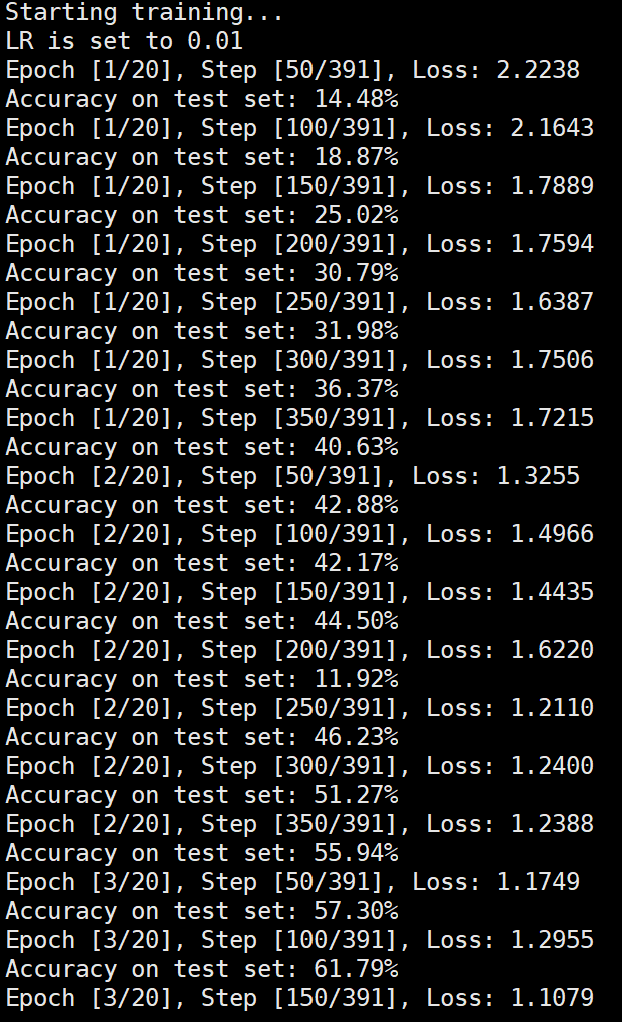
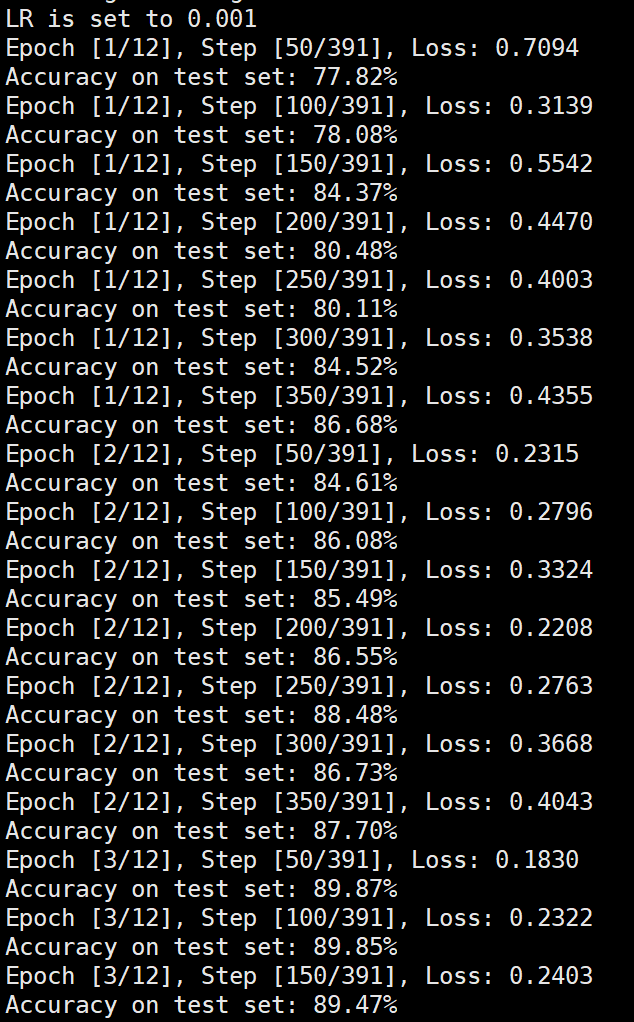
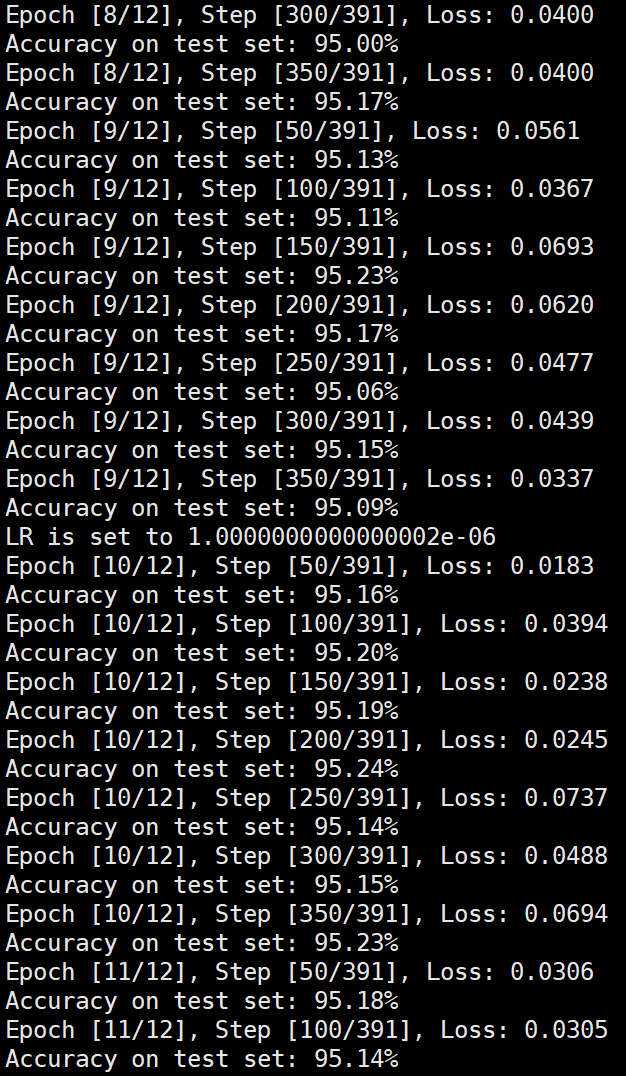
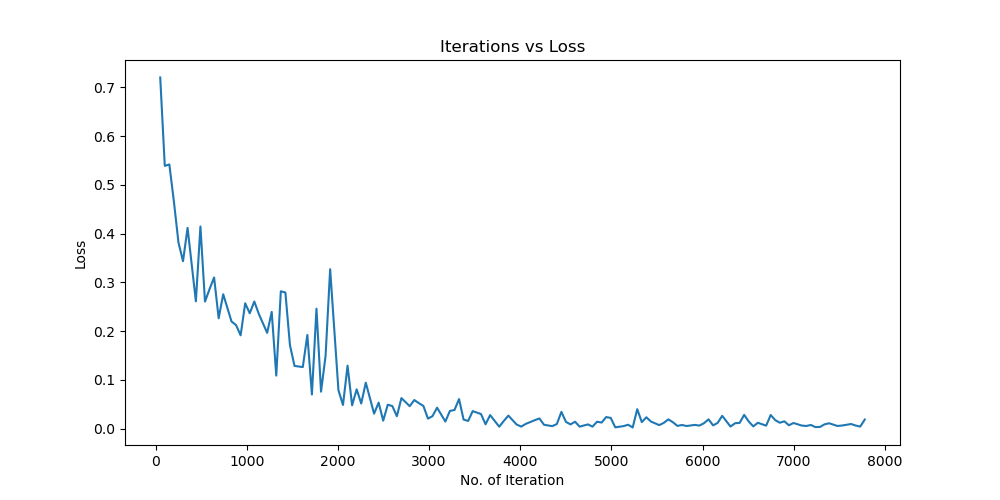
由实验结果可得lr=0.01时,效果较差,所以直接设置初始学习率为0.001可以更节省时间,提高效率。当学习率为1e-6时,发现准确率更新较小,所以准确率最小设置为1e-6。即学习率梯度为1e-3,1e-4,1e-5,1e-6,可以有较好的效果。即令epoch / lr_decay_epoch = 3或4 都可以,具体以epoch大小为准。
lr=0.01
lr=0.001
lr=1e6
batchsize分析
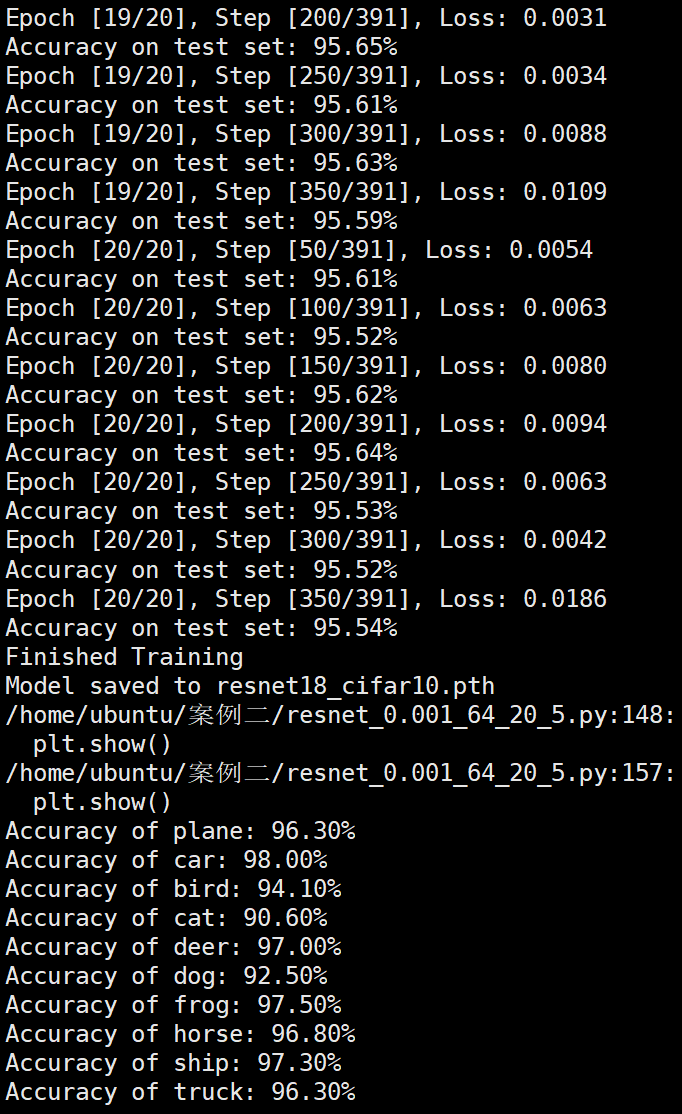
Batchsize:64 epoch:6 lr_decay_epoch:2 初始学习率为0.001 94.46%
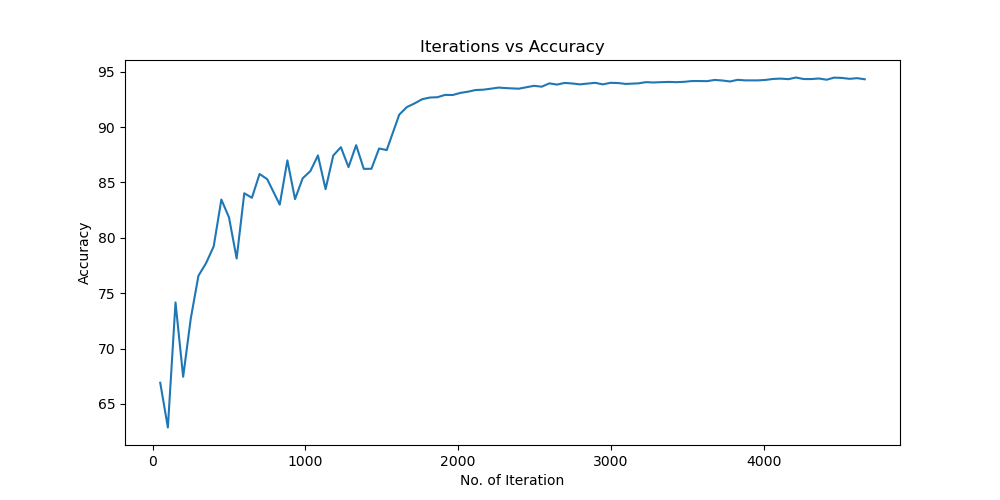
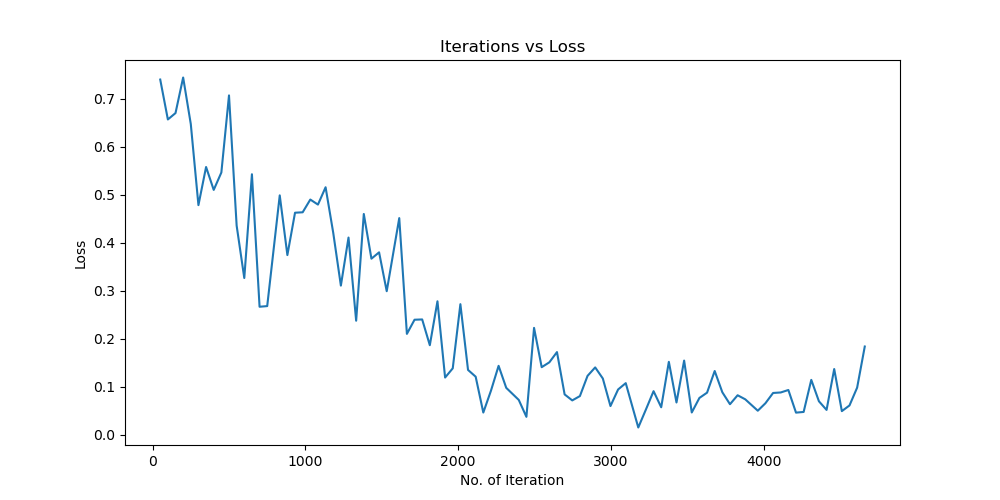
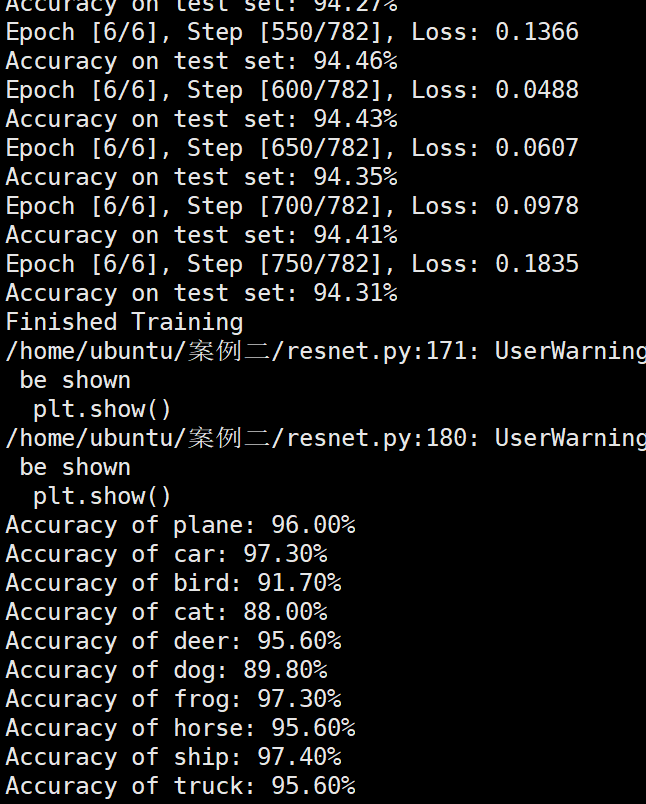
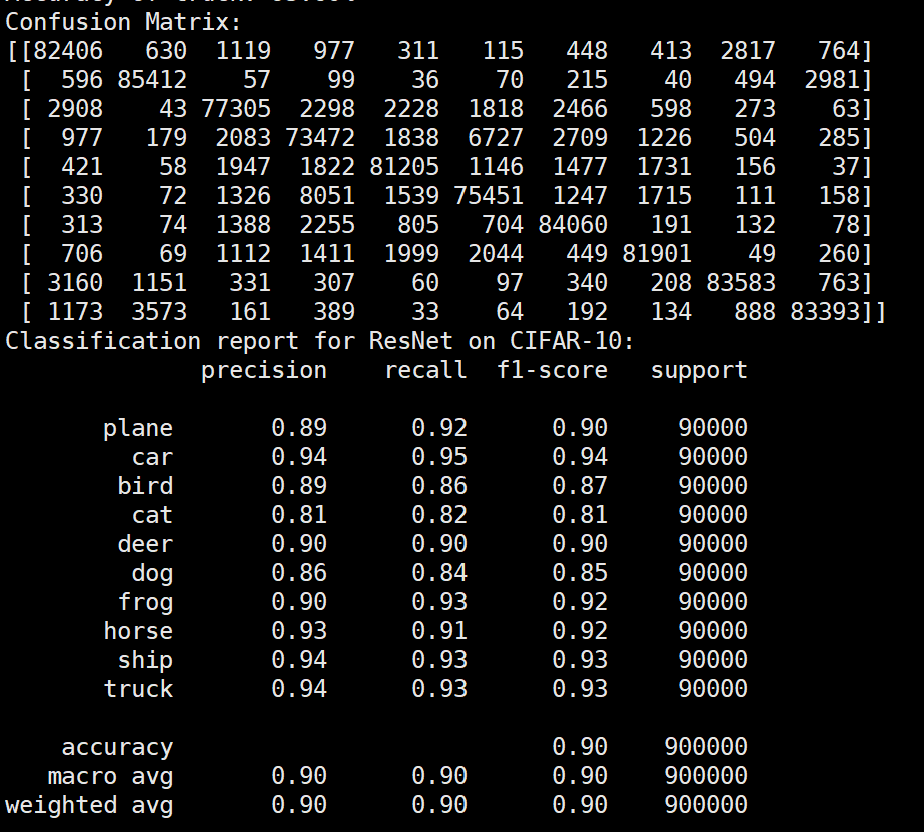
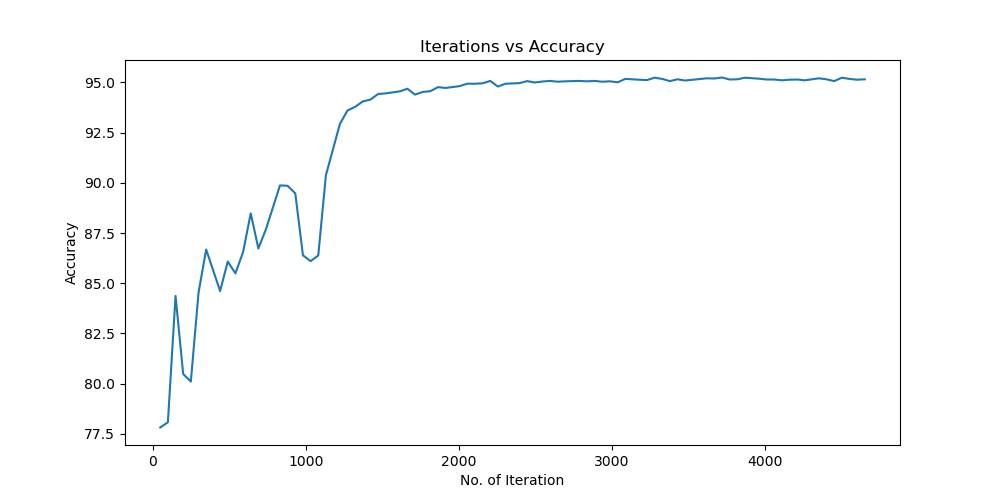
Batchsize:128 epoch:12 lr_decay_epoch:3 初始学习率为0.001 95.23%
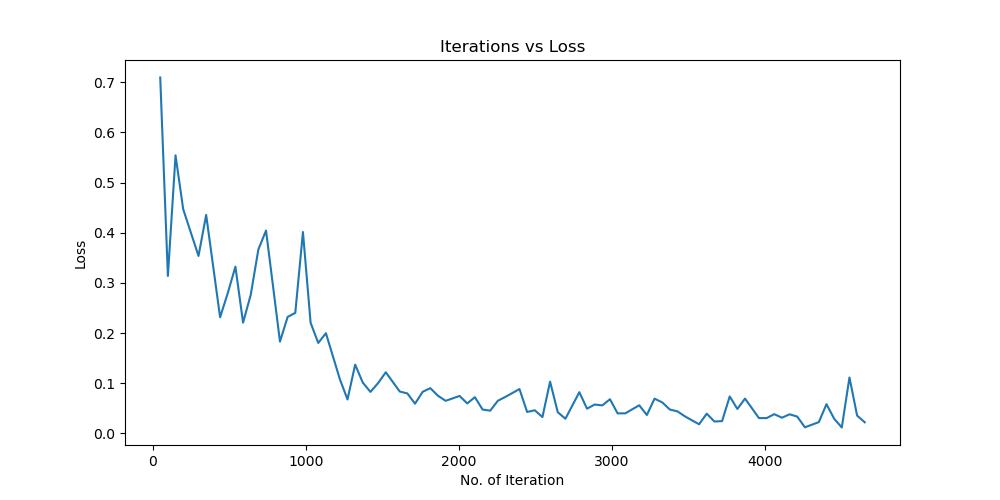
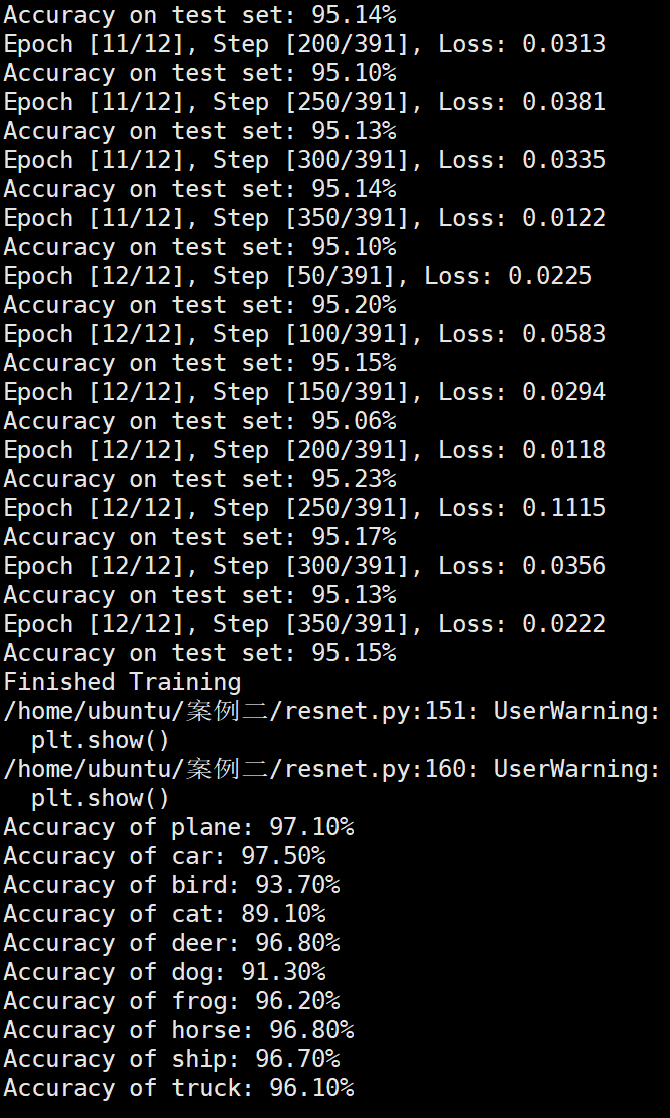
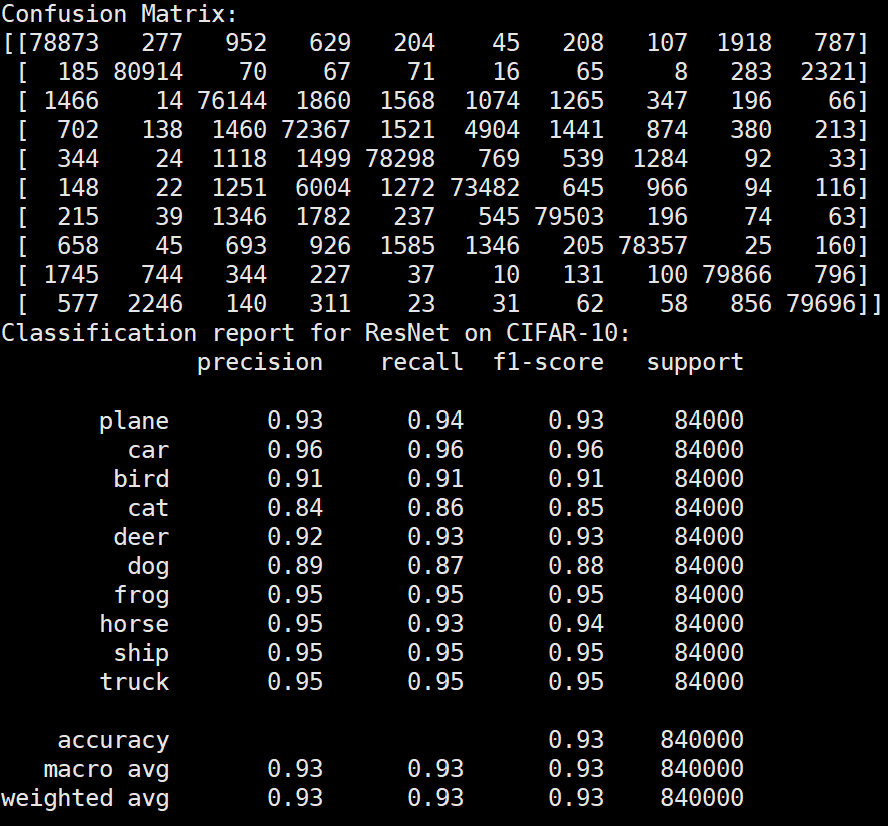
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为0.01 85.87%
和分析的一致,对比下面实验,控制变量,只有初始学习率改变,精度提升10%左右。
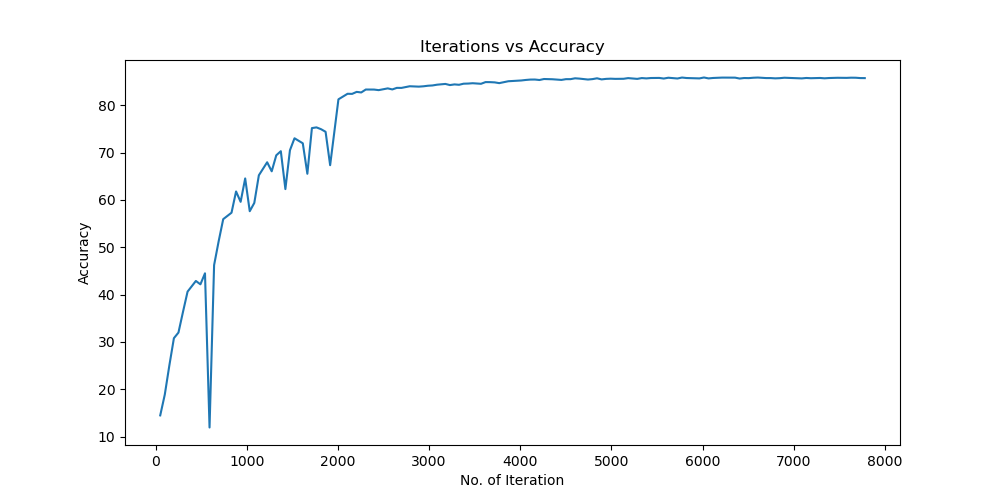
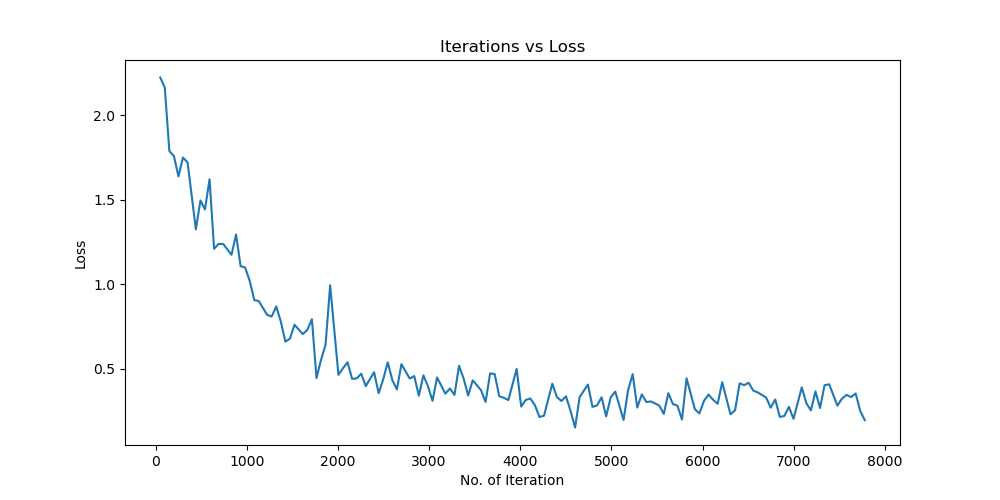
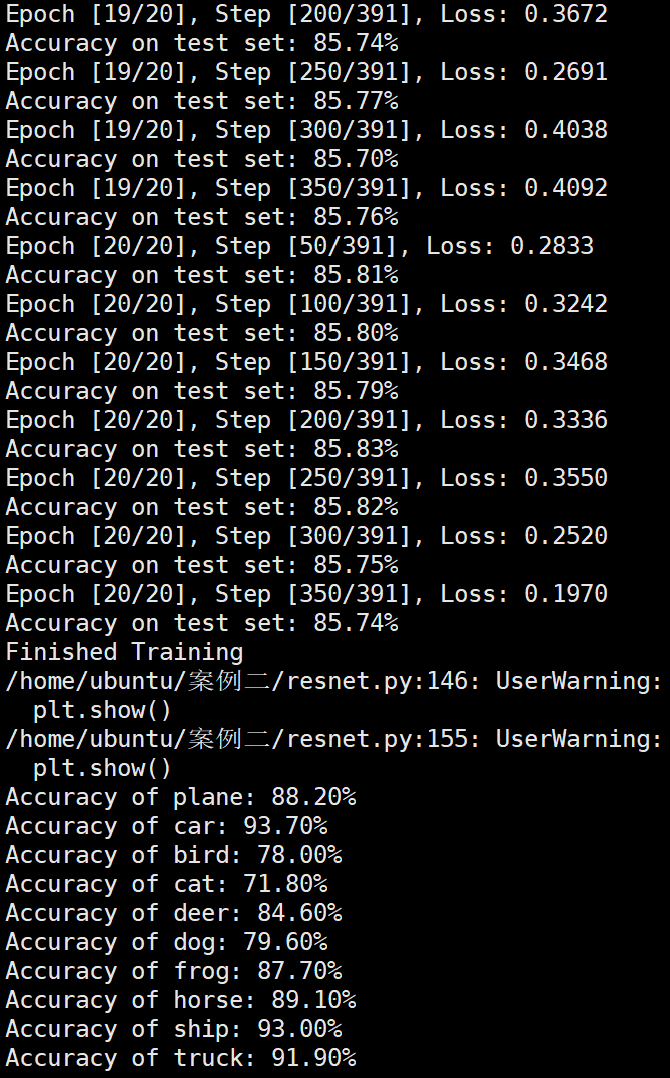
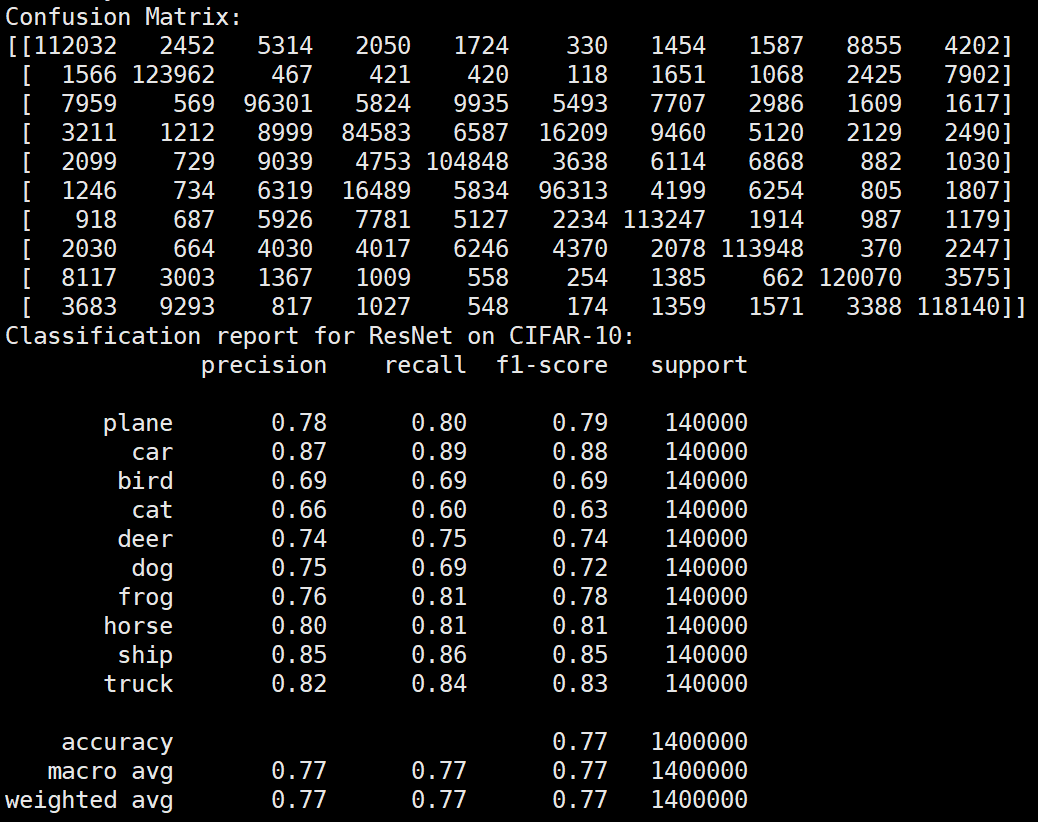
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为0.001 95.44%
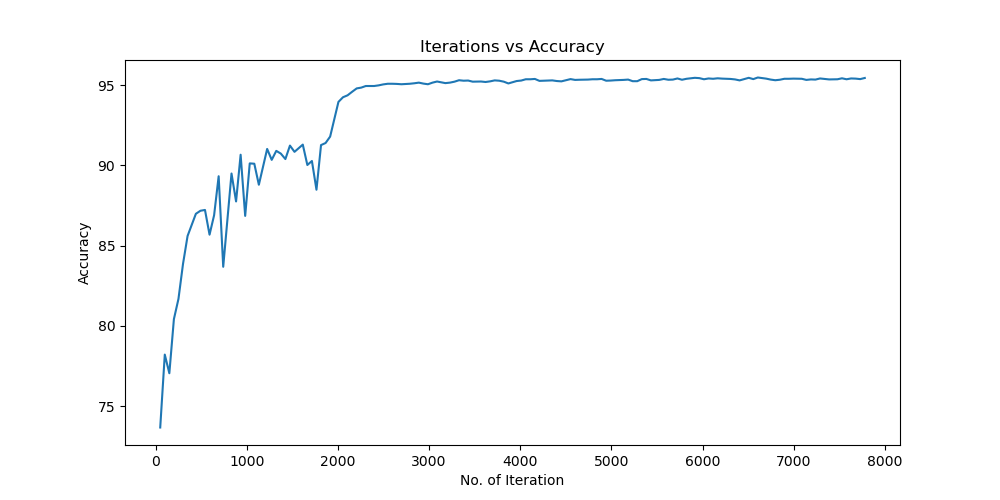
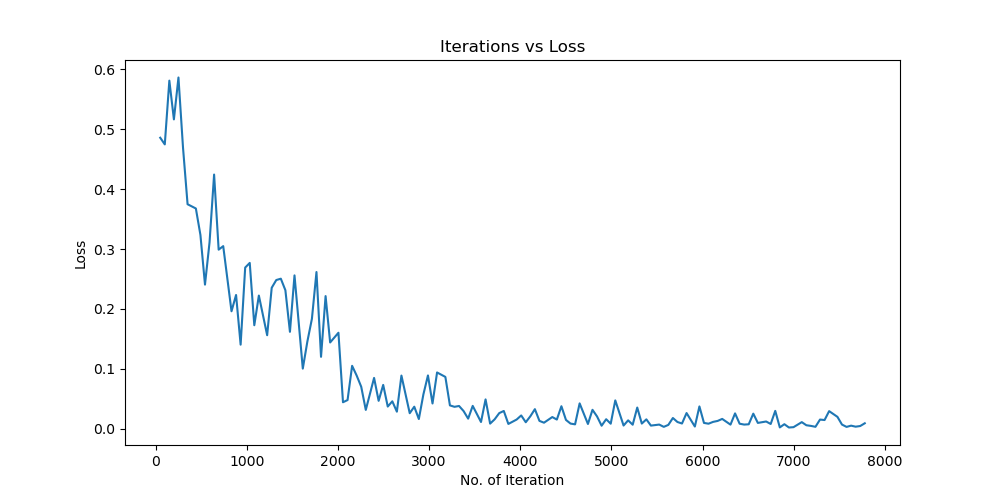
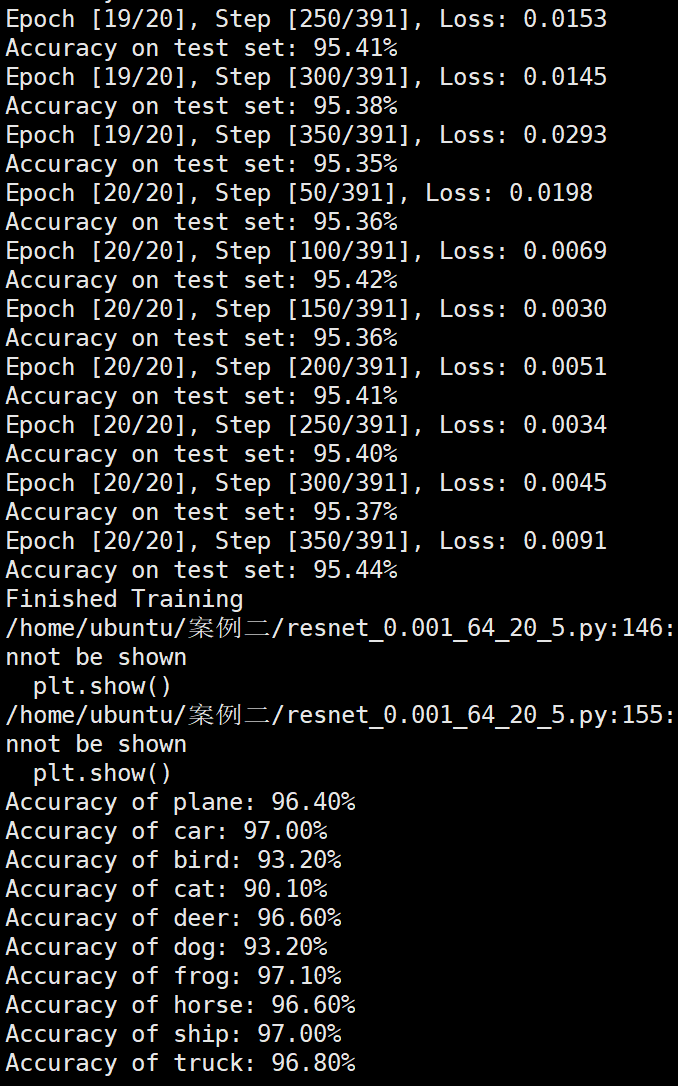
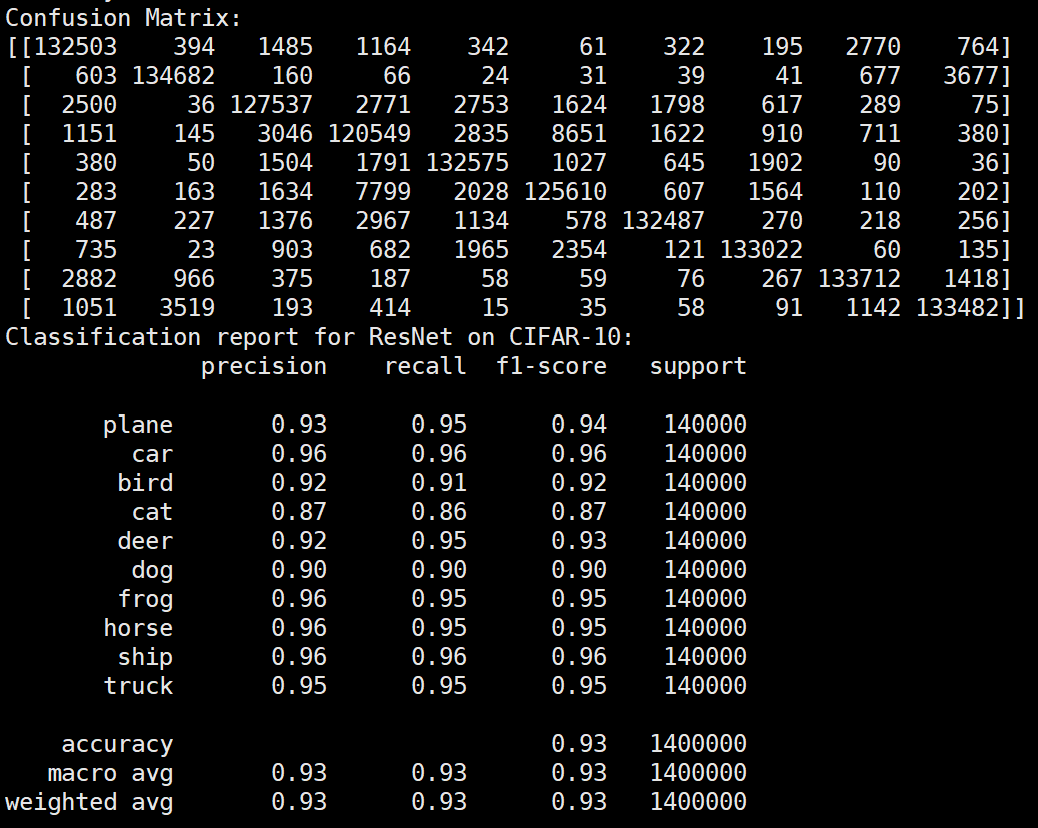
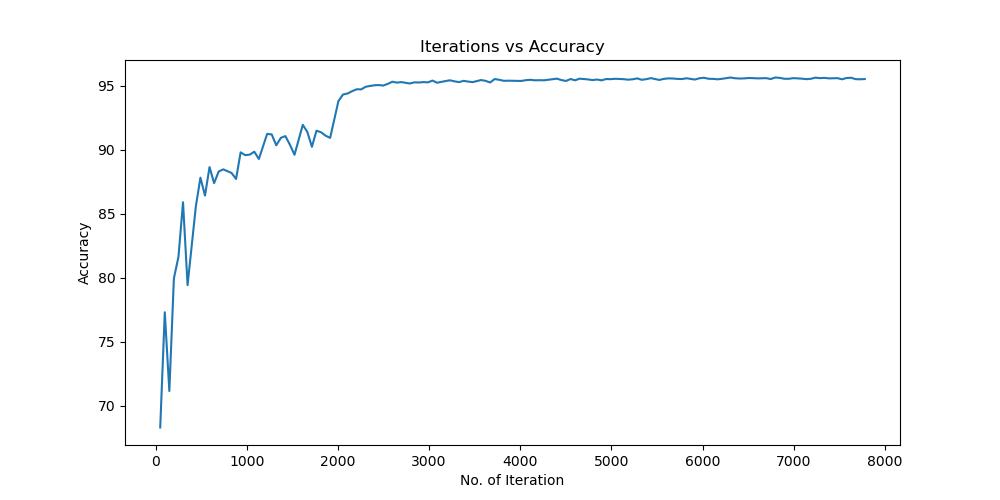
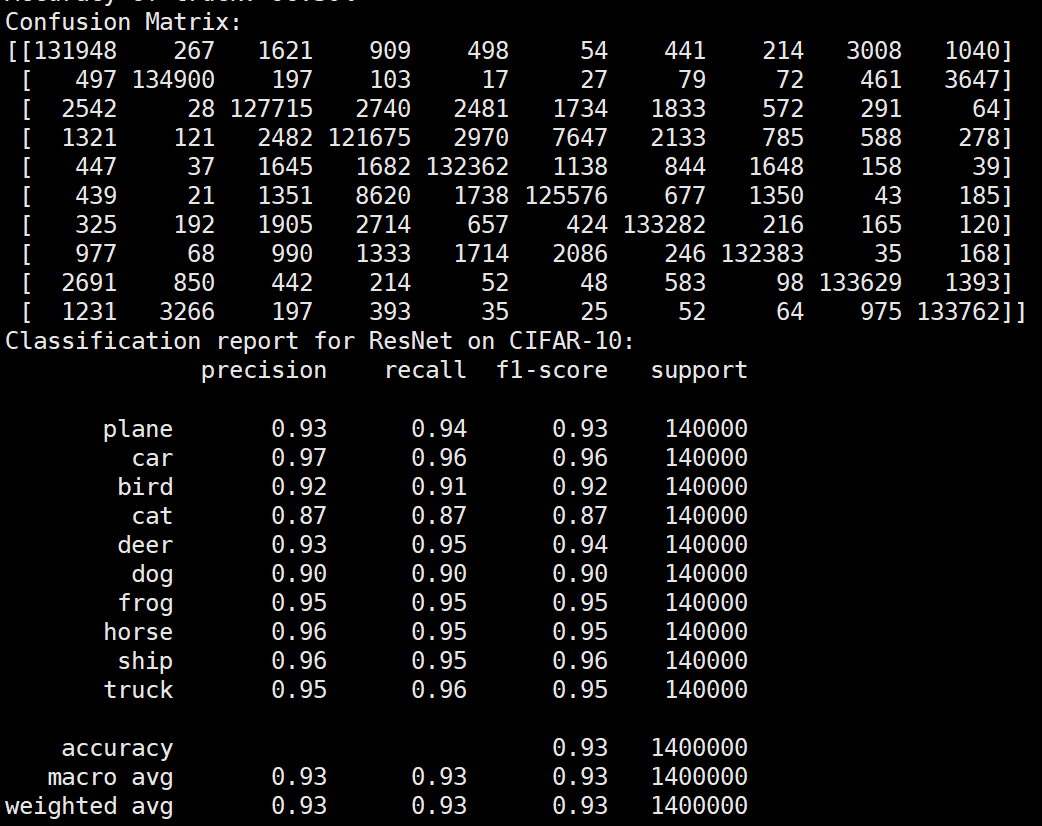
Batchsize:64 epoch:20 lr_decay_epoch:5 初始学习率为0.001 95.66%
使用LeNet网络
与Resnet相比换了一个网络和改了数据加载模块,其他没啥变化。
库函数导入
1 | import matplotlib.pyplot as plt |
数据集加载及增强操作
1 | transform = transforms.Compose( |
LeNet模型
1 | class C1(nn.Module): |
模型训练超参数设置
1 | #定义损失函数,初始学习率,优化器 |
模型训练
1 | num_epochs = 20 |
实验结果保存
1 | torch.save(model.state_dict(), 'lenet5_cifar10.pth') |
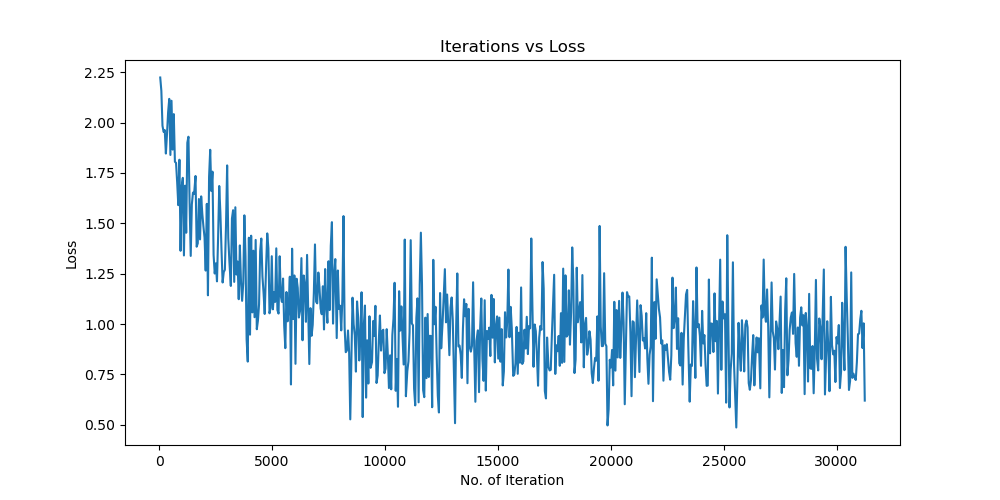
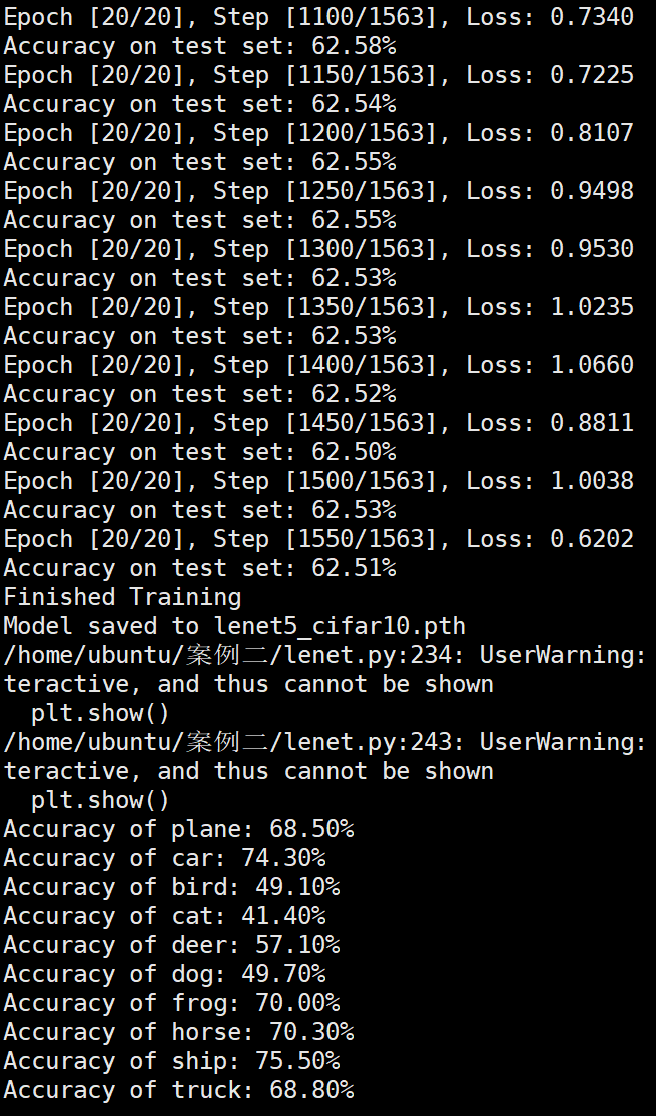
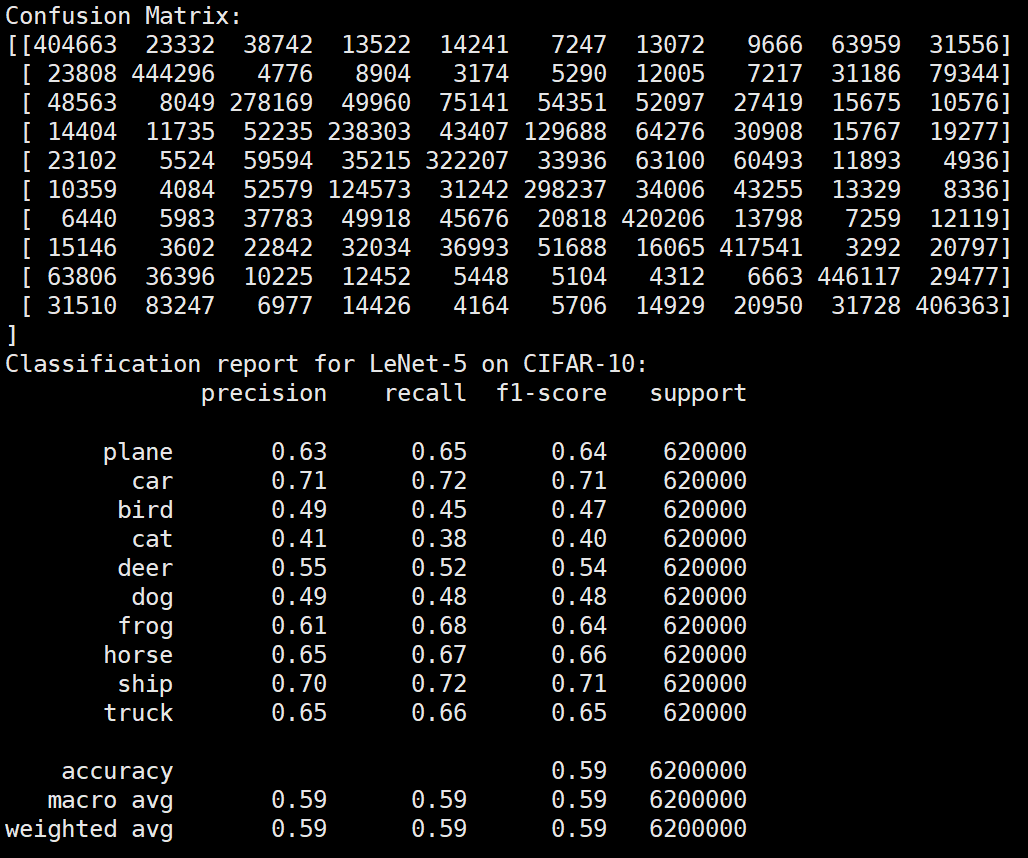
实验结果分析
使用图像增强操作
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 60.56%
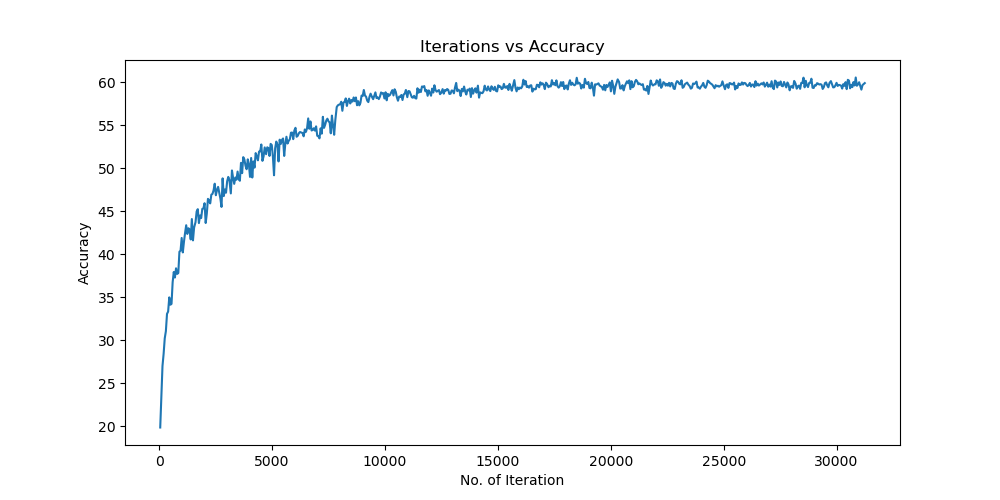
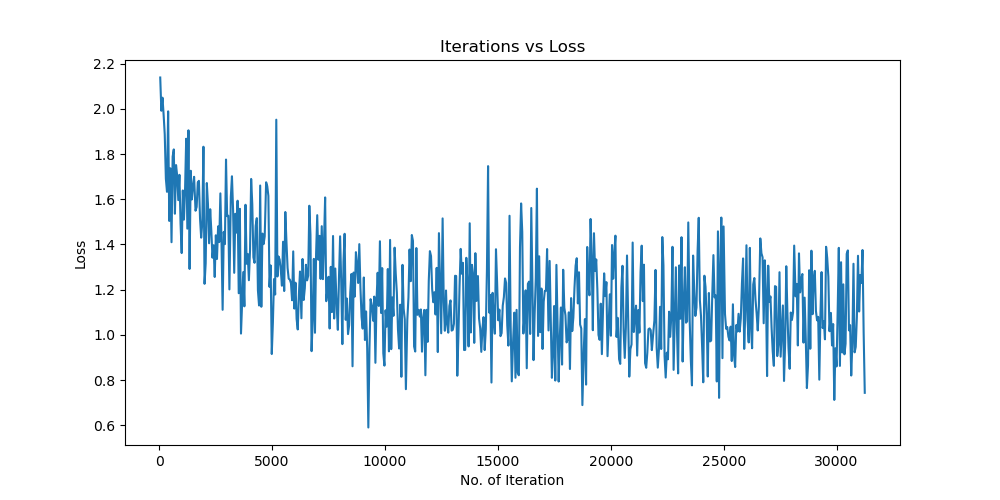
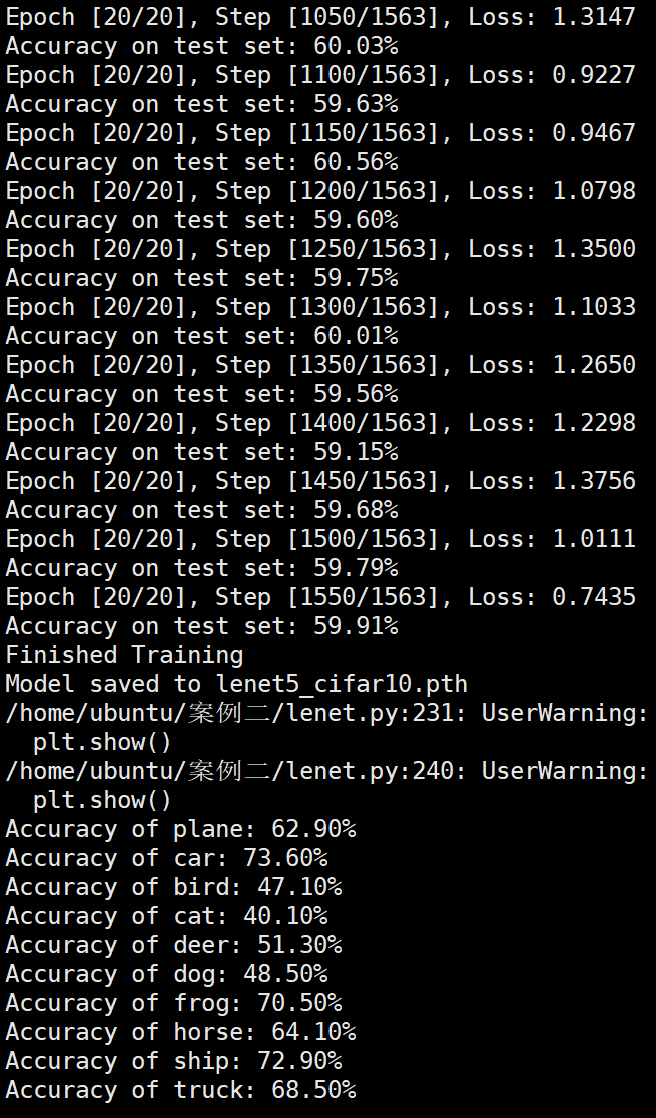
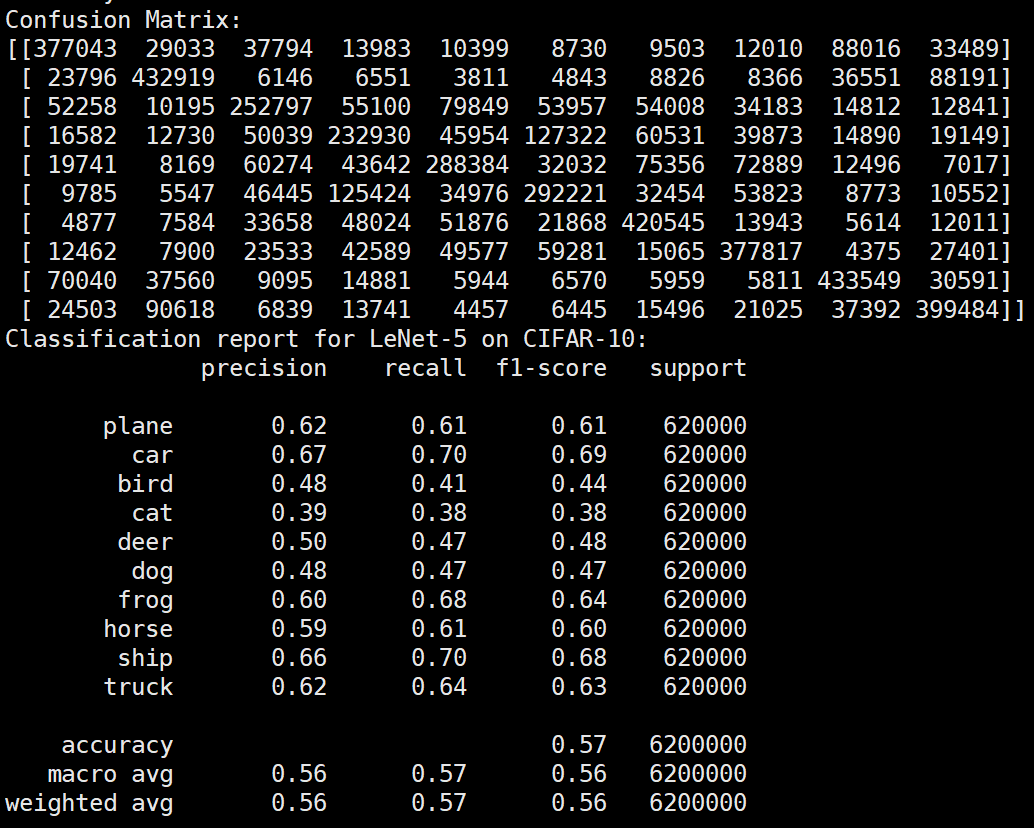
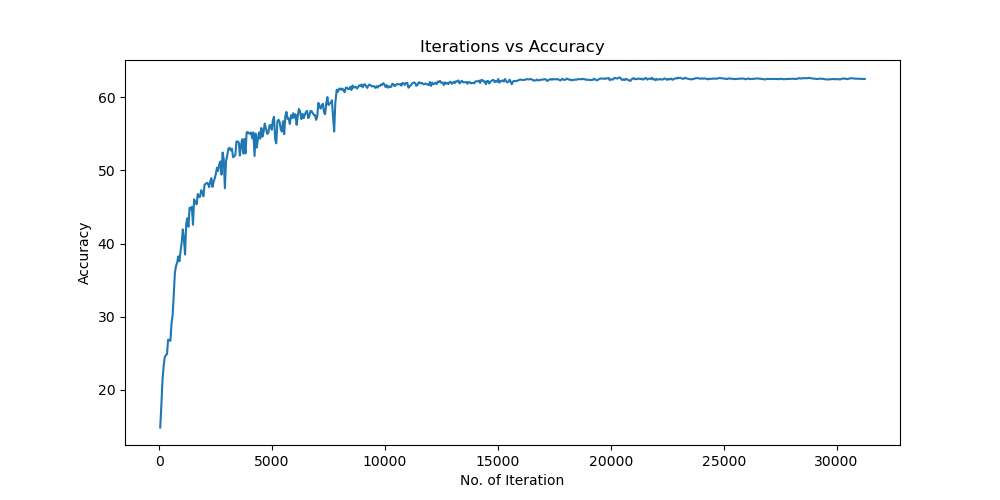
未使用图像增强操作
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 62.66%
使用FashionNet
代码详见github
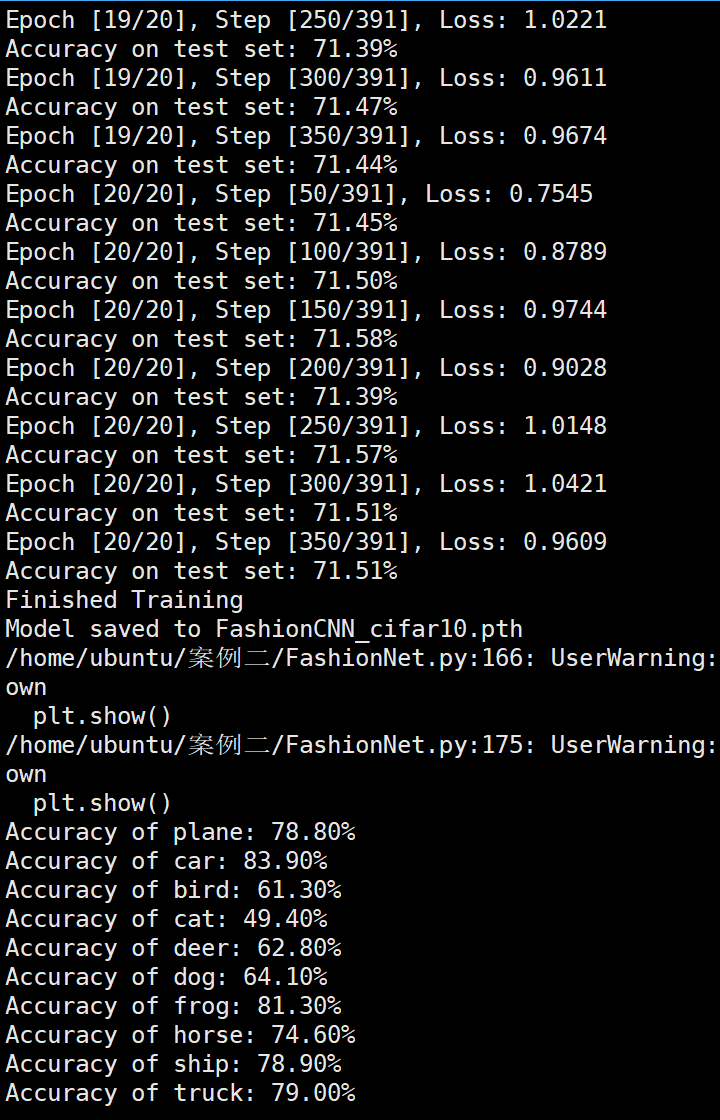
图像增强操作训练结果分析
使用图像增强操作
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 71.51%
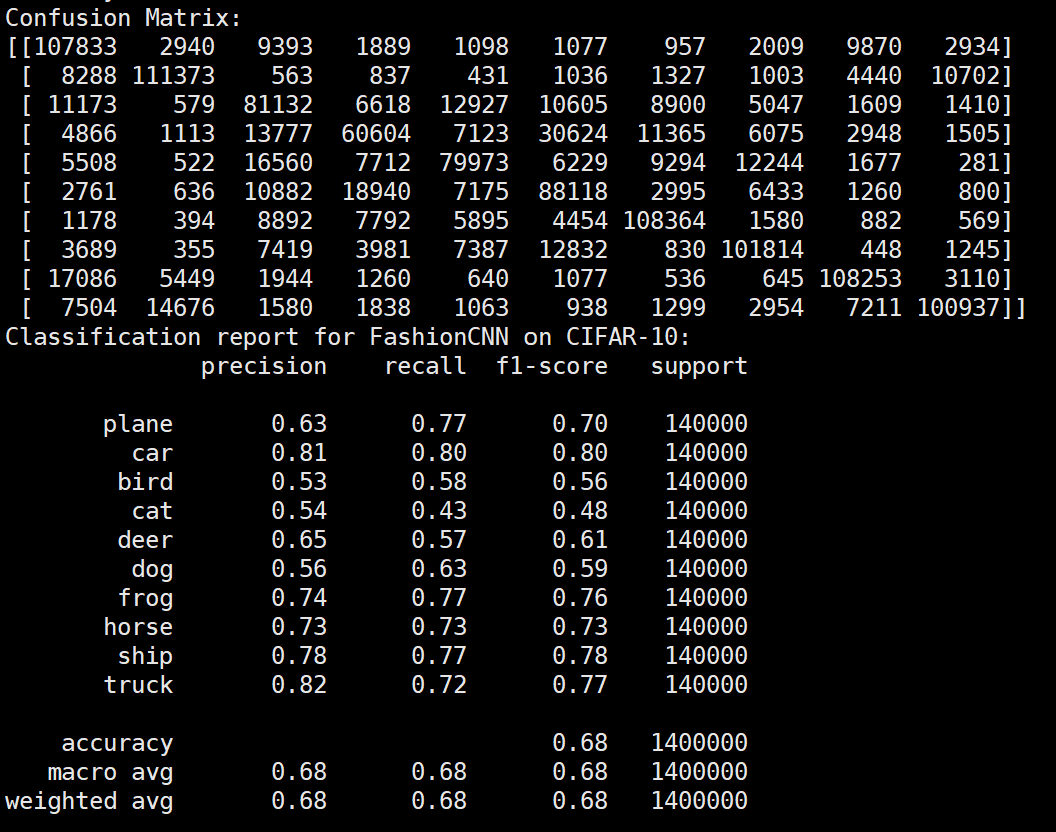
未使用图像增强操作
Batchsize:128 epoch:30 lr_decay_epoch:6 初始学习率为 0.01 71.69%
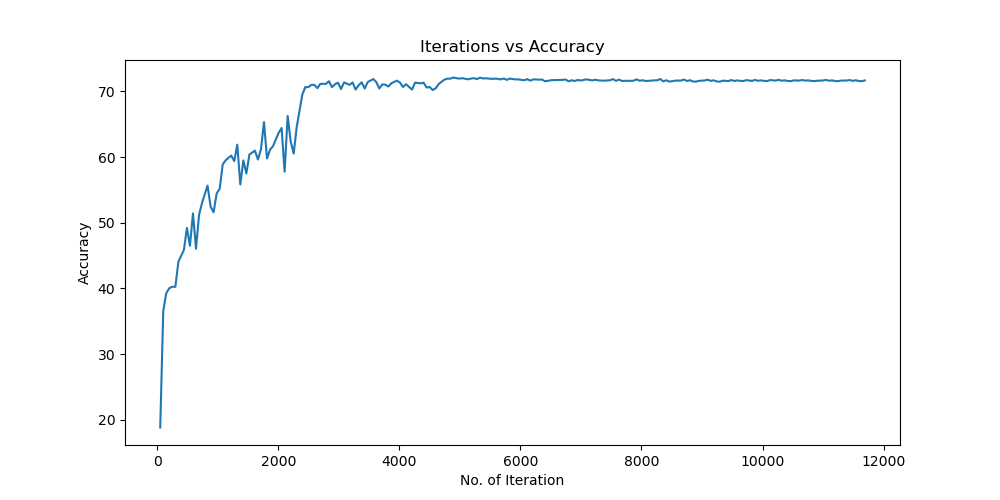
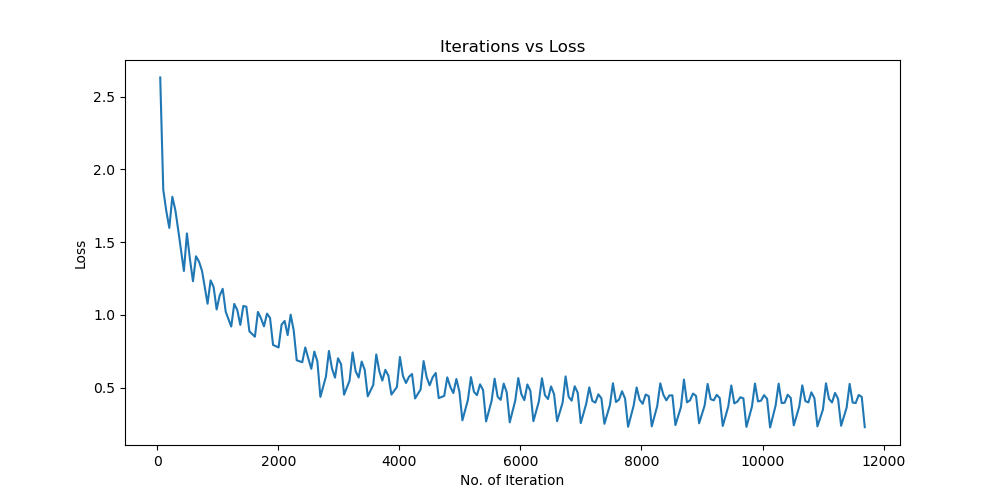
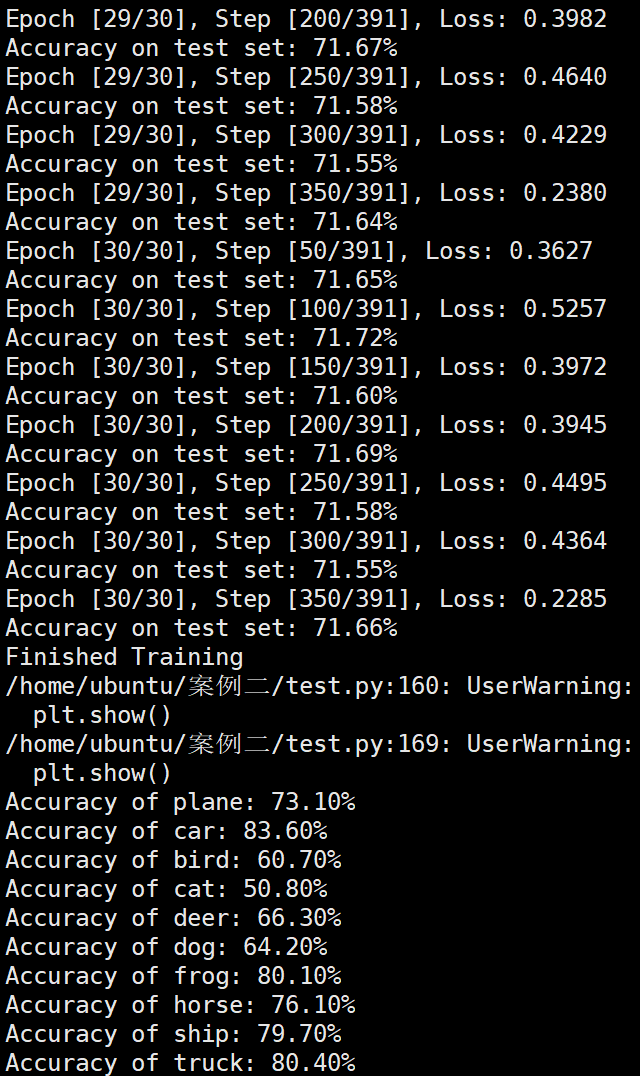
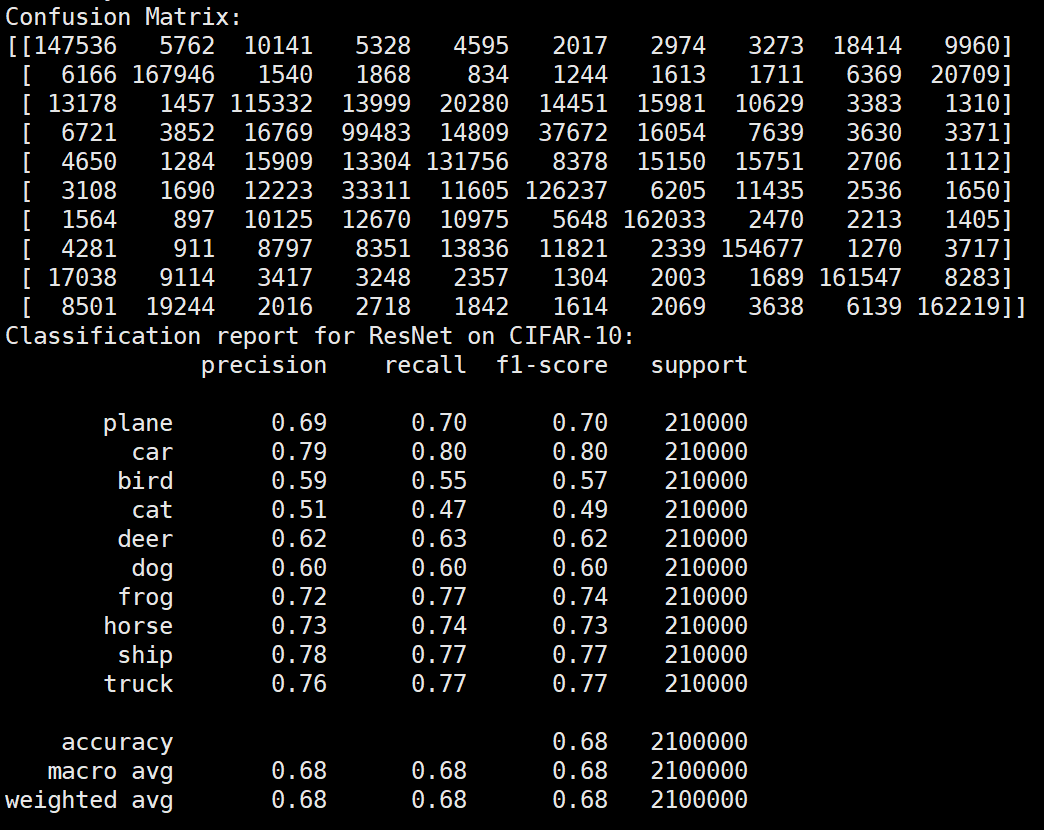
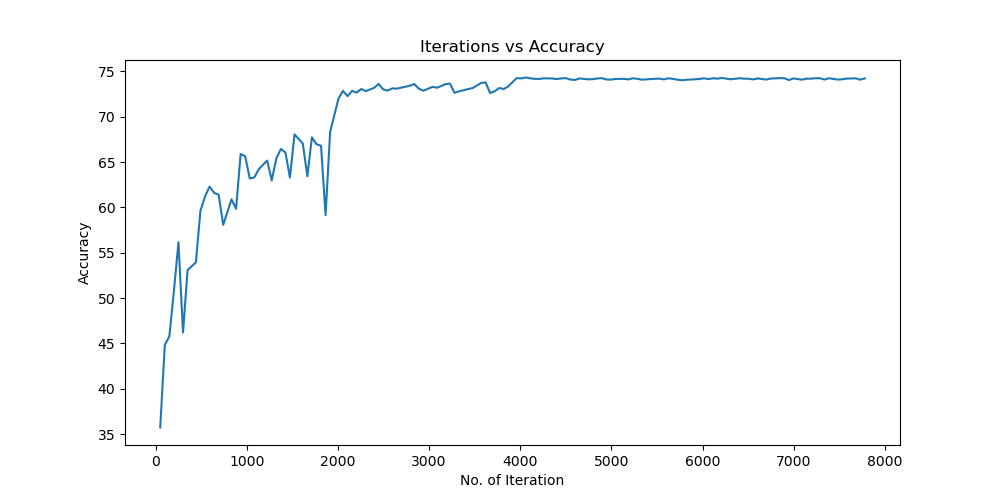
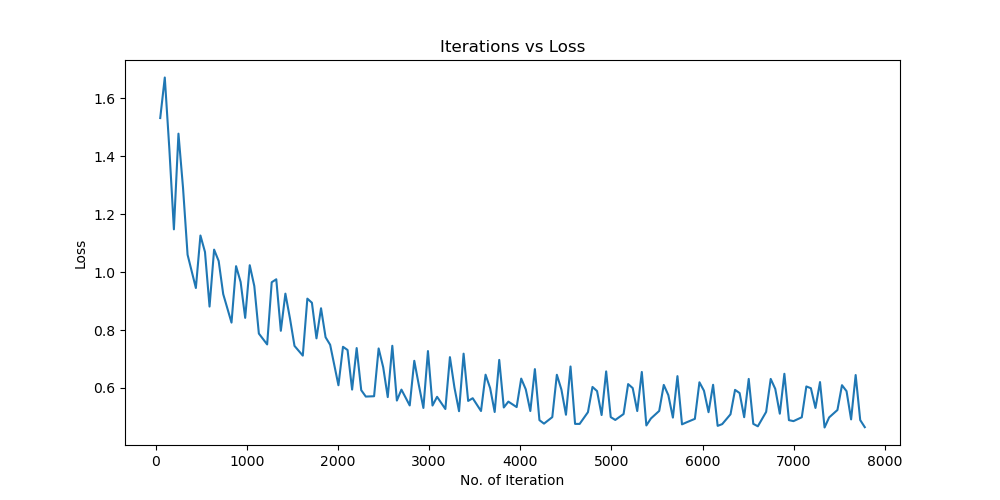
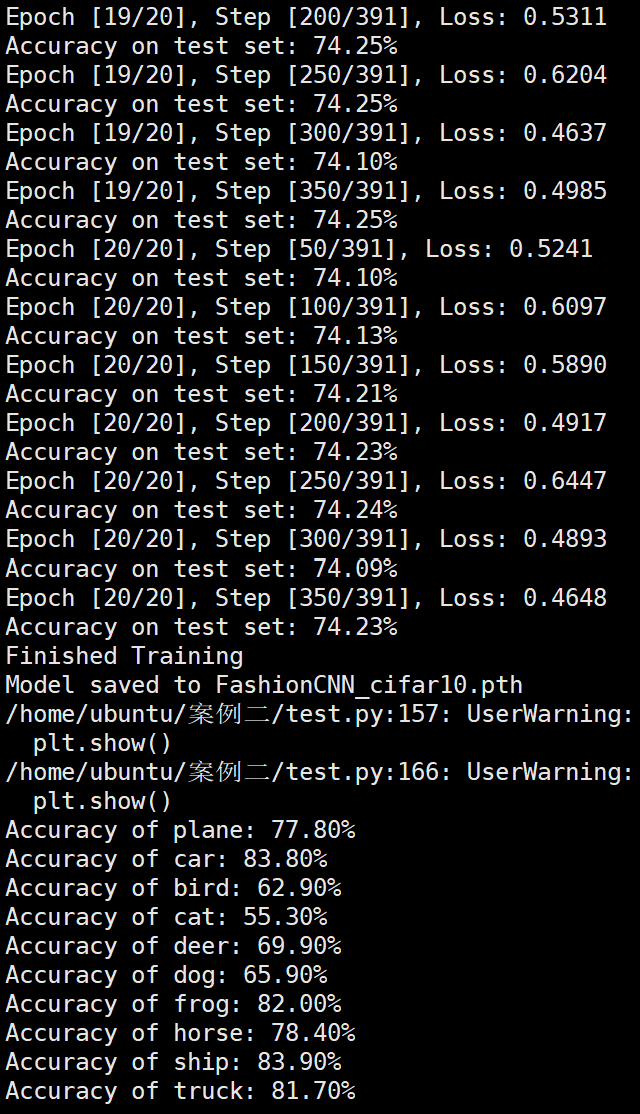
Batchsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 74.25%
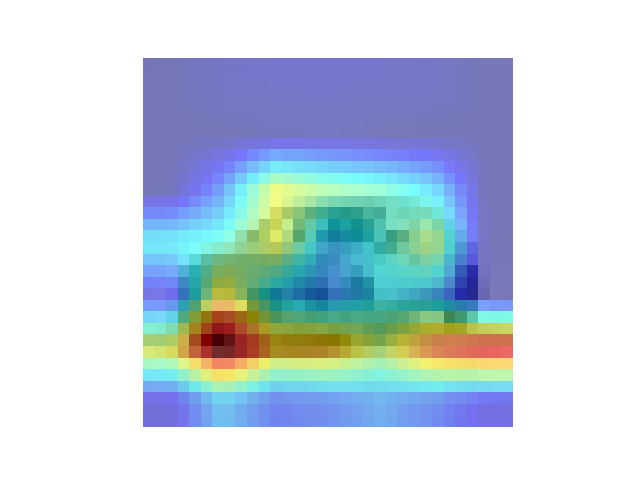
Gradcam实现图像特征可视化
Grad-CAM 的目标层均为最后一个卷积层
Resnet效果图
参数配置 Batch_size:64 epoch:20 lr_decay_epoch:5 lr:0.001 95.66%
图片来自谷歌。




FashionNet效果图
参数配置 Bachsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 74.25%

LeNet效果图
参数配置 Bachsize:128 epoch:20 lr_decay_epoch:5 初始学习率为 0.001 60.56%


总结
数据集在不同模型上的准确率
| 模型 | 准确率 |
|---|---|
| ResNet | 95.66% |
| LeNet | 62.66% |
| FashionNet | 74.25% |
LeNet对数据集进行图像增强操作的影响
分析:由于模型过于简单,本来就会出现欠拟合现象,继续进行图像增强操作后会导致模型更加欠拟合。所以出现三个模型精度差距较大,主要是因为模型复杂度的差距。虽然是欠拟合,但是继续增加epoch也并不会提高精度,因为模型对数据已经学到了尽可能多的知识。
| 未归一化 | 归一化 | 图像增强操作 | 大量图像增强操作 |
|---|---|---|---|
| 58.75% | 62.66% | 60.56% | 56.78% |
神经网络参数对模型准确率的影响
batch_size:64或128并无太大影响。
初始学习率:由实验结果可得lr=0.01时,效果较差,三个网络都使用了0.01进行测试得出的结果,有的实验结果没贴图。所以直接设置初始学习率为0.001可以更节省时间,提高效率。当学习率为1e-6时,发现准确率更新较小,所以准确率最小设置为1e-6。即学习率梯度为1e-3,1e-4,1e-5,1e-6,可以有较好的效果。
lr_decay_epoch和epoch:即学习率梯度为1e-3,1e-4,1e-5,1e-6,可以有较好的效果。即令epoch / lr_decay_epoch = 3或4 都可以,具体以epoch大小为准。
 微信
微信
